The Wall I Hit on Google's Highest AI Plan




It was a Wednesday afternoon. I'd just opened Antigravity to build out a feature branch with Gemini 3.1 Pro. New capability, a database migration, end-to-end tests. Nothing exotic. The kind of work I've shipped a hundred times.
Halfway through the migration, the model cut me off. Quota exhausted. I checked the dashboard and every model I had access to was either at zero or on its way there. Gemini 3.1 Pro: locked for over an hour. Claude Opus: four hours. Even Flash was running low. I'm paying for Google's AI Ultra plan. The highest tier they sell. And it was Wednesday afternoon.
So I switched to Flash to keep moving. Within minutes it broke the migration Gemini had started. Different assumptions about the schema, different naming patterns, a confidently wrong rewrite of a function it hadn't written. Two hours of repair work for what should have been a clean handoff. By the time I was done, I'd spent more time fixing Flash's mistakes than the original feature would have taken to write by hand.
That's when it hit me. The real bottleneck in AI-assisted product work isn't model quality. It's not prompting skill. It's the structural mismatch between how these tools are billed and how real product work actually flows.
The Subscription Hides the Real Cost
The pricing pages talk about tokens, requests, and tier limits. The dashboards show you green bars and yellow bars (and yes, yellow means zero, not twenty percent, which is its own quiet outrage). What none of it tells you is the workflow tax.
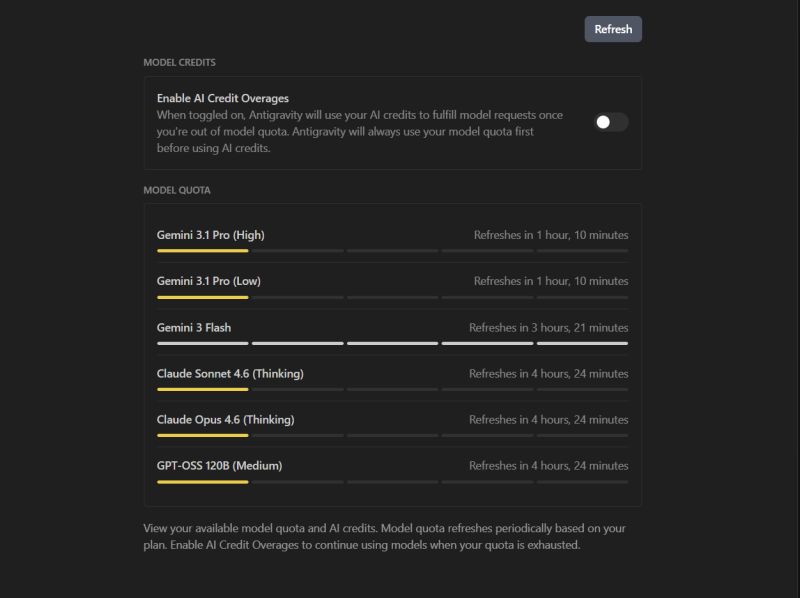
 Every quota reset you wait for is momentum lost. Every model switch is context lost. Every downgrade introduces a quieter, more expensive kind of debt: code written by a model that didn't understand the patterns the previous model established, sitting in your branch, waiting to surface as a regression three days from now.
Every quota reset you wait for is momentum lost. Every model switch is context lost. Every downgrade introduces a quieter, more expensive kind of debt: code written by a model that didn't understand the patterns the previous model established, sitting in your branch, waiting to surface as a regression three days from now.
Anthropic is throttling Claude during peak hours. Google's top tier runs dry mid-afternoon. The pattern is the same everywhere. The tools got smarter. The constraints got tighter, faster. And the cost of those constraints doesn't show up on the invoice. It shows up in the half-finished branches, the rewritten migrations, the features that took a day instead of an hour.
The real cost of AI in product work isn't the subscription. It's the compounding tax on every workflow that assumed the model would still be there when you came back.
What These Tools Were Optimized For
If you step back, the mismatch makes sense. The current generation of coding agents was built for short, stateless interactions. Ask a question, get an answer. Refactor a function, ship a snippet. The interaction model assumes you bring the context in your head and the model fills in the local detail.
Real product work doesn't run that way. A feature is a chain of decisions: schema, migration, API surface, error handling, tests, observability. Each one builds on the last. Each one carries assumptions the next step needs to honor. The work compounds.
When you hand that compounding work to a stateless tool with a hard quota, two things happen. The tool runs out before the work does. And when you switch models to keep going, the new model has no idea what the old one was doing. It guesses. Sometimes it guesses well. Often it doesn't.
That's the structural failure. It isn't that the models are bad. It's that the system around them treats every interaction as if it stands alone, when in practice every interaction is the middle of something.
What Gets Lost in the Handoff
The thing that disappears in a model switch isn't the code. The code is right there in the diff. What disappears is the implicit context the previous model was operating under. The naming choices it made. The error-handling pattern it picked. The migration path it had half-committed to but hadn't yet written down.
A human collaborator would have those things in their head, and you'd recover them in a five-minute standup. With a model, there's no head to ask. The context lives in the conversation history, and the new model doesn't have access to that history in any way that helps it reason about your branch.
So you end up doing one of two things. You write a long, careful prompt to bring the new model up to speed, which costs time and tokens and is never quite complete. Or you let the new model guess, watch it confidently overwrite the old model's choices, and pay the debugging tax later.
Either way, the feature you were building stops being a feature. It becomes a translation problem.
Treating Models Like Teammates, Not Tools
The fix I've landed on is to stop treating AI tools as a single continuous collaborator and start treating them as a rotating team. If the team is going to rotate, the work has to be designed for handoffs.
In practice that has meant a few changes to how I structure a session:
- Break features into smaller, self-contained commits that survive a model switch
- Keep a running context document the next model can onboard from
- Front-load the hard architectural decisions before the quota runs out
- Treat model switches like team handoffs, explicit, not implicit
None of this is novel. Any senior engineer who has worked across time zones has done some version of it. What's new is that the rotating teammate isn't another human. It's the same product, sold to me at the highest tier, that happened to run out of capacity at 2:14 p.m. on a Wednesday.
The shift in mindset matters more than the tactics. Once you stop expecting persistent context from the tool, you start building it yourself. The branch becomes the source of truth. The commit history becomes the handoff document. The model becomes one collaborator among several, none of whom remember anything you didn't write down.
The Next Wave Isn't a Better Model
Most of the conversation about AI in product work is still about models. Which one is smarter at code, which one is faster, which one ships next. That's the easy thing to argue about because it's measurable and it changes every six weeks.
The harder, slower thing is the system around the models. The persistent context layer. The handoff protocol between sessions. The way a team's accumulated product knowledge survives a quota reset, a model switch, or a tool migration. That's where the actual leverage is, and almost none of the current tooling treats it as a first-class problem.
I think the next wave of useful AI tooling for product work won't be a better coding model. It'll be better systems for managing how we use the ones we have. Persistent product context that any model can onboard from. Workflow design that assumes interruption. Commit and handoff patterns that treat the AI like a member of a distributed team.
The Wednesday afternoon wall isn't a quota problem. It's a system design problem hiding behind a quota. And the teams that figure out the system design first are going to ship circles around the ones still arguing about which model writes the prettiest function.
Related Posts


Product Upate: May 2026 - Close the Loop
Outcomet's Validation Tree, Roadmap canvas, and Delivery Alpha connect product discovery, planning, and delivery into one graph, with Nova acting across all of it.


The Question Five Agents Never Asked
This week five AI agents worked for me in parallel for thirty minutes. The idea was half-botched from the start. They executed it beautifully anyway, and not one of them stopped to ask whether we were building the right thing. That missing question turned out to be the whole job.

Discovery Is Three Jobs Wearing One Word
A B2B team I watched ran textbook discovery: prototype, show, learn, adjust, repeat. The loop was clean. It still walked us into a wall, because one word was hiding three completely different jobs and we were only doing one of them.